


Flow Chart :
✔Project Execution Flow Create an S3 Bucket for Raw Data --> ✔Load data using the CLI commands -->✔Create a Crawler and Crawl Open the Data --> ✔Create Glue Catalog -->✔ Error with the Json Format(Serde) -->✔ Pre-processing the data --> ✔Json-to-parquet-transformation -->✔ Run a crawler again --> ✔query in Athena for analytics --> ✔Create a new DB for the Target --> ✔Crate a new Glue Job(Do necessary transformations such as dropping null fields, and arranging the schema) --> ✔Add a S3 Trigger to Orchestrate --> ✔*Create a Glue Job To Join(inner) tables -->*✔ *Load data to Final Target -->*✔ Quicksight/Tableau for Visualizations
🔍 I've been on a journey to securely manage, streamline, and analyze YouTube's trending video data 📺📊.
Objective:
Data Ingestion: Developing a mechanism to seamlessly gather data from diverse sources.
ETL System: Transforming raw data into the required format for analysis and storage.
Data Lake: Establishing a centralized repository to efficiently store data from multiple sources.
Scalability: Ensuring our system dynamically scales to handle growing data volumes effectively.
Cloud Integration: Leveraging AWS to process and manage vast datasets exceeding local computing capabilities.
🌐 Data Sources: This project tapped into a treasure trove of daily trending YouTube videos across regions like the United States, Great Britain, Germany, Canada, and France 🌎📹. It's been an eye-opener, with insights on up to 200 trending videos per day in each of these regions.
🛠️ Services Used:
📦 Amazon S3: Known for its scalability, data availability, robust security, and exceptional performance.
🔐 AWS IAM: Identity and Access Management for secure AWS service and resource management.
🧩 AWS Glue: A serverless data integration service simplifying data prep and aggregation.
💡 AWS Lambda: Enabling code execution without the hassle of managing servers.
🔍 AWS Athena: An interactive query service tailored for Amazon S3.
✂ NLTK: To remove unnecessary words and preprocess text data for further analysis like with ML models.
📌 RNN: Used RNN model to predict the category of the title entered again by users.
🔑Key Points:
1. Data Lake architecture in the below picture is Centralize the repository to store all things

We created a DataLake of S3 bucket with a specific naming convention and enabled server-side encryption for data protection. Upload data to the S3 bucket using AWS CLI command.
Step 1 : Go to the below link for sample content data
Step 1.1 : Create your S3 bucket through the console or CLI and paste these commands after downloading your content.
#Replace It With Your Bucket Name
# To copy all JSON Reference data to same location:
aws s3 cp . s3://data-on-youtube-raw-dev/youtube/raw_statistics_reference_data/ --recursive --exclude "*" --include "*.json"
# To copy all data files to its own location, following Hive-style patterns:
aws s3 cp CAvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=ca/;
aws s3 cp DEvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=de/;
aws s3 cp FRvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=fr/;
aws s3 cp GBvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=gb/;
aws s3 cp INvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=in/;
aws s3 cp JPvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=jp/;
aws s3 cp KRvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=kr/;
aws s3 cp MXvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=mx/;
aws s3 cp RUvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=ru/;
aws s3 cp USvideos.csv s3://data-on-youtube-raw-dev/youtube/raw_statistics/region=us/;

Step 1.2 : Create a crawler, crawl over all your json files, and run your crawler.

Insights:
AWS Glue and Glue Data Catalog:
A crawler is used to populate the AWS Glue Data Catalog with tables. Crawlers can crawl multiple data stores in a single run. ETL jobs that you define in AWS Glue use these Data Catalog tables as sources and targets. AWS Glue Data Catalog is a managed metadata repository that stores and organizes metadata. It is used to define the structure and schema of your data during the glue etl job.
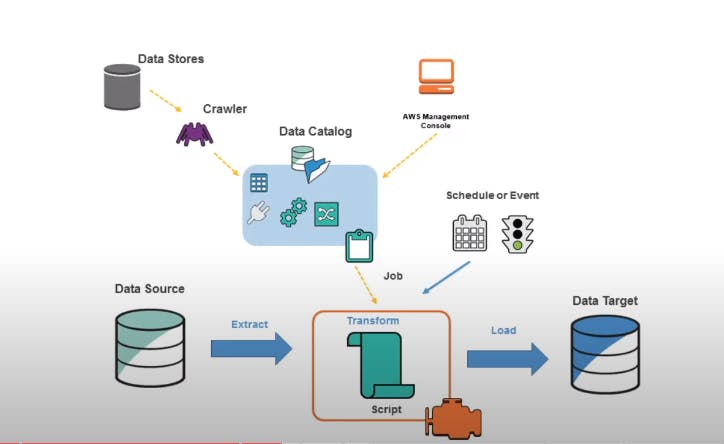
Purpose of Glue Data Catalog
Problem: Athena is not smart enough to understand what data we want to pick.
Amazon says it only read json which is in specific format i.e {key:value} which mean it should be in one line, all curli braces , content should be in one line.
if you provide a file like below
{ "key" : 10 } { "key" : 20 }it will not understand it and when you try to query it through Athena it will throw you an error.

So we need to perform some cleaning actions

Note: We need to add one more layer to our function AWSDataWrangler-Python3.8 and replace it with AWSSDKPandas-Python3.8 version 10
```python import awswrangler as wr import pandas as pd import urllib.parse import os
os_input_s3_cleansed_layer = os.environ['s3_cleansed_layer'] os_input_glue_catalog_db_name = os.environ['glue_catalog_db_name'] os_input_glue_catalog_table_name = os.environ['glue_catalog_table_name'] os_input_write_data_operation = os.environ['write_data_operation']
def lambda_handler(event, context):
Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') try:
Creating DF from content
df_raw = wr.s3.read_json('s3://{}/{}'.format(bucket, key))
Extract required columns:
df_step_1 = pd.json_normalize(df_raw['items'])
Write to S3
wr_response = wr.s3.to_parquet( df=df_step_1, path=os_input_s3_cleansed_layer, dataset=True, database=os_input_glue_catalog_db_name, table=os_input_glue_catalog_table_name, mode=os_input_write_data_operation )
return wr_response except Exception as e: print(e) print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket)) raise e
4. Define your environment variables by your choice

5. Also, you need to create the above database in the catalog.
6. After running your above script, your JSON file will transfer to the desired S3 location with all the transformations.

7. Now we can successfully query our data through Athena.

```python
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
predicate_pushdown = "region in ('ca','gb','us')"
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "youtube-raw-data", table_name = "youtube_videos", transformation_ctx = "datasource0", push_down_predicate = predicate_pushdown)
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("video_id", "string", "video_id", "string"), ("trending_date", "string", "trending_date", "string"), ("title", "string", "title", "string"), ("channel_title", "string", "channel_title", "string"), ("category_id", "long", "category_id", "long"), ("publish_time", "string", "publish_time", "string"), ("tags", "string", "tags", "string"), ("views", "long", "views", "long"), ("likes", "long", "likes", "long"), ("dislikes", "long", "dislikes", "long"), ("comment_count", "long", "comment_count", "long"), ("thumbnail_link", "string", "thumbnail_link", "string"), ("comments_disabled", "boolean", "comments_disabled", "boolean"), ("ratings_disabled", "boolean", "ratings_disabled", "boolean"), ("video_error_or_removed", "boolean", "video_error_or_removed", "boolean"), ("description", "string", "description", "string"), ("region", "string", "region", "string")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
datasink1 = dropnullfields3.toDF().coalesce(1)
df_final_output = DynamicFrame.fromDF(datasink1, glueContext, "df_final_output")
datasink4 = glueContext.write_dynamic_frame.from_options(frame = df_final_output, connection_type = "s3", connection_options = {"path": "s3://youtube-proj-cleansed-data/cleansed-data/", "partitionKeys": ["region"]}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
"Thank You for Reading!"
We sincerely appreciate you taking the time to read our blog. We hope you found the information valuable and that it helped you in your journey. Your interest and engagement mean a lot to us.
If you have any questions, feedback, or if there's a specific topic you'd like us to cover in the future, please don't hesitate to reach out. We're here to assist and provide you with the necessary knowledge and insights.
Remember, your support is what keeps us motivated to continue creating content. Stay curious, keep learning, and thank you for being a part of our community!
Warm regards,
Chetan Sharma